论文地址:https://arxiv.org/abs/2602.13344
说明:这是一篇论文学习记录,我是阅读者,不是本文作者。内容以原文信息为主,辅以我的理解与重组,尽量保留细节方便后续复习。
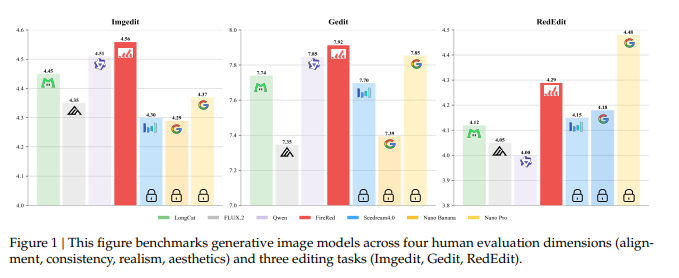
一、论文想解决什么问题(阅读视角)
当前图像编辑路线主要有三类痛点:
- 闭源黑盒模型难以复现和研究;
- 开源模型参数规模持续增大,不利于训练与部署;
- 业界偏向蒸馏黑盒能力,但原生高质量数据和评测基准不足。
我的理解是:这篇工作不是单点“模型结构创新”,而是尝试把数据、训练、评测三个环节一起拉齐,去解决图像编辑落地过程中的系统性短板。
二、主要贡献(按原文主线整理)
- 数据层面:构建 1 亿规模图像编辑训练数据(文生图与图生图约 1:1),数据来源覆盖真实数据与合成数据,并强调清洗、打标、后验质量控制。
- 训练层面:给出从预训练、持续预训练、SFT 到偏好优化和 RL 的全生命周期训练策略(含多种训练 tricks)。
- 评测层面:提出 REDEdit-Bench,覆盖 15 类图像编辑任务,并补足传统 benchmark 与用户体感之间的落差。

三、数据工程:从“海量”到“可训练”
3.1 预清洗与真实数据保真
原文给出的真实数据清洗链路是:
全局去重 -> 画质筛选 -> 内容维清洗(水印/覆盖文本) -> 感知分筛选
并强调尽量去除 AIGC 生成图,以提高真实样本占比。
3.2 数据生成 pipeline(补齐真实数据覆盖盲区)
原文提到:自然数据无法覆盖所有 I2I 编辑场景,因此采用了三类方案:
- 专家指令库 + 编辑目标词典
- 指令库把约束与触发条件抽象成规范原语和结构化槽位,提升稳定性;
- 目标词典结合 VLM 探测、任务清单与辅助元数据(如 OCR、坐标)做 grounding。
- 结构化控制下的专家模型合成
- 借助 SAM、DWpose 等感知模块提取分割掩码、关键点等结构先验;
- 在空间敏感任务(如精准移除、姿态迁移、外观重定向)中更有效。
- 无模型模板合成
- 3D 参数化模板(表情/姿态等可控变化);
- 结构化布局模板(文字、Logo、UI 元素空间锚点);
- 算法滤波模板(锐化、色彩重定向等底层增强)。
3.3 长尾增补、三级打标与后清洗
对长尾数据,原文提到采用 check-and-fill:先聚类,再通过文搜图/图搜图从全量库检索并补齐小众类目。
打标方面,基于 VLM 的三级标注为:
详细指令 -> 精确指令优化 -> 用户风格指令
并将“简洁指令 + 精细描述”混合训练,以覆盖从口语短指令到高细节长指令的分布。
后清洗部分保留了不少关键细节:
- 构建 5 万正样本三元组(源图-指令-目标图);
- 用 LLM 语义扰动得到 5 万负样本;
- 对 10 万样本做专业双盲标注,核心指标是指令对齐度与感知质量;
- 用上述数据微调评估模型(以 Qwen3-VL-8B 为骨干);
- 再对超亿级数据做自动化质量筛选(指令对齐分 + 视觉质量分)。
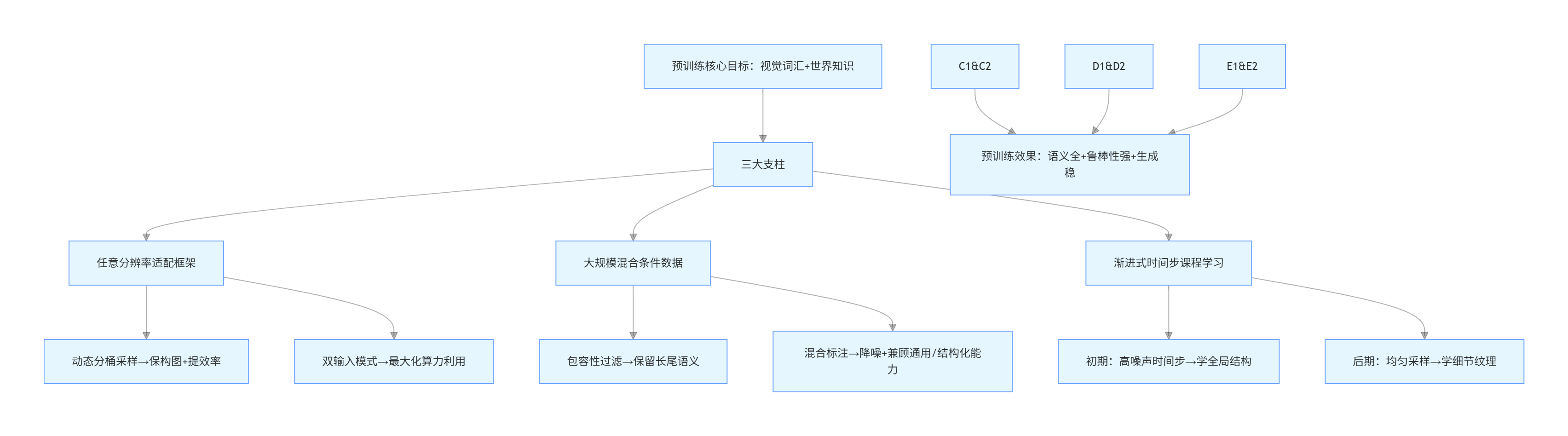
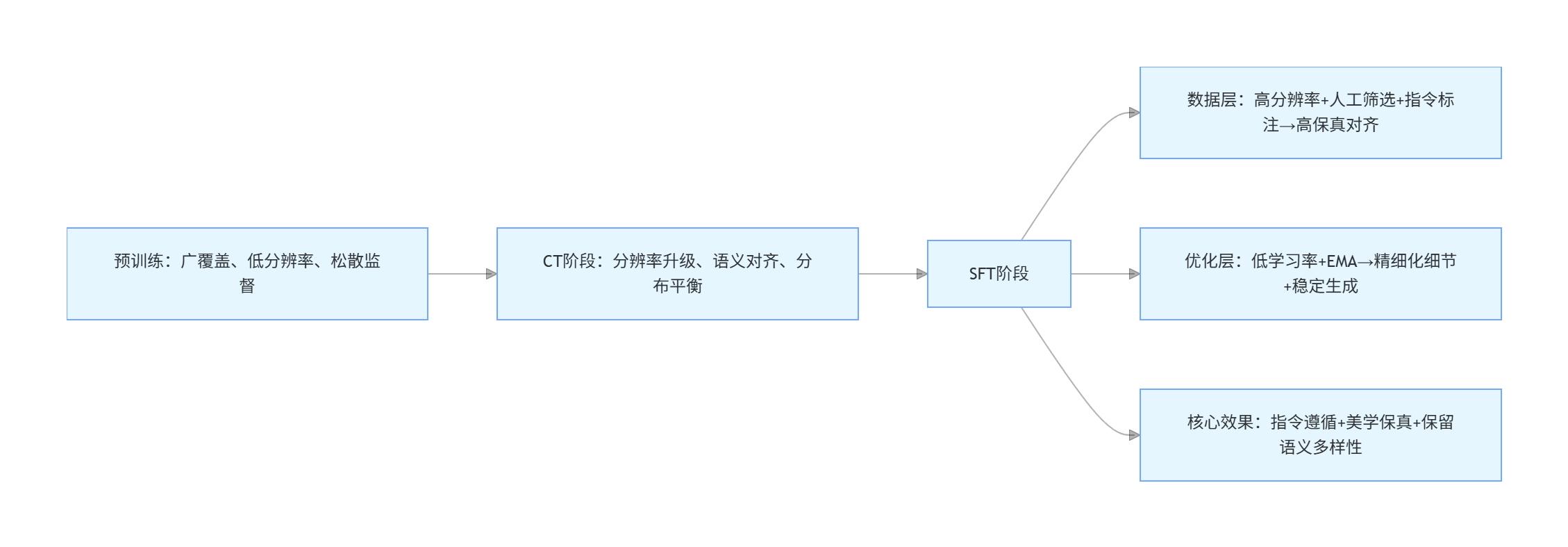
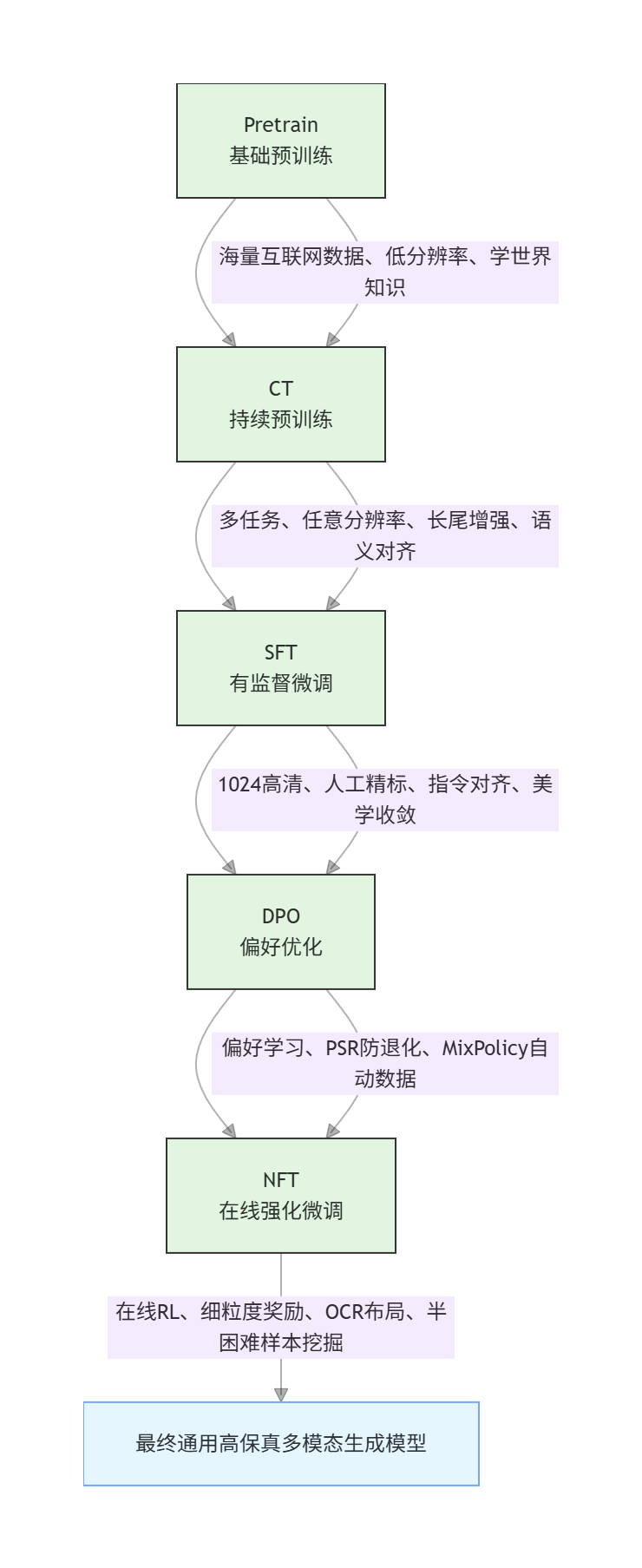
四、训练策略:全生命周期优化(细节版)
4.1 整体训练阶段
原文 pipeline 覆盖:
- Pretrain
- Continued Pretrain
- SFT
- DPO
- NFT
并在不同阶段逐步提升分辨率与指令标注强度。学习时我记录的关键配置如下:
- 分辨率:从 384-512 逐步到 1024;
- 训练步数:Pretrain 30 万,CT 6.5 万,SFT 5 千,DPO 5 千,NFT 500;
- 优化器:AdamW(全阶段);
- 梯度裁剪:1;
- 权重衰减:0.01。

4.2 分阶段策略理解
- 预训练阶段:强调任意分辨率适配、混合条件数据、渐进式时间步课程学习(先学全局,后学细节)。
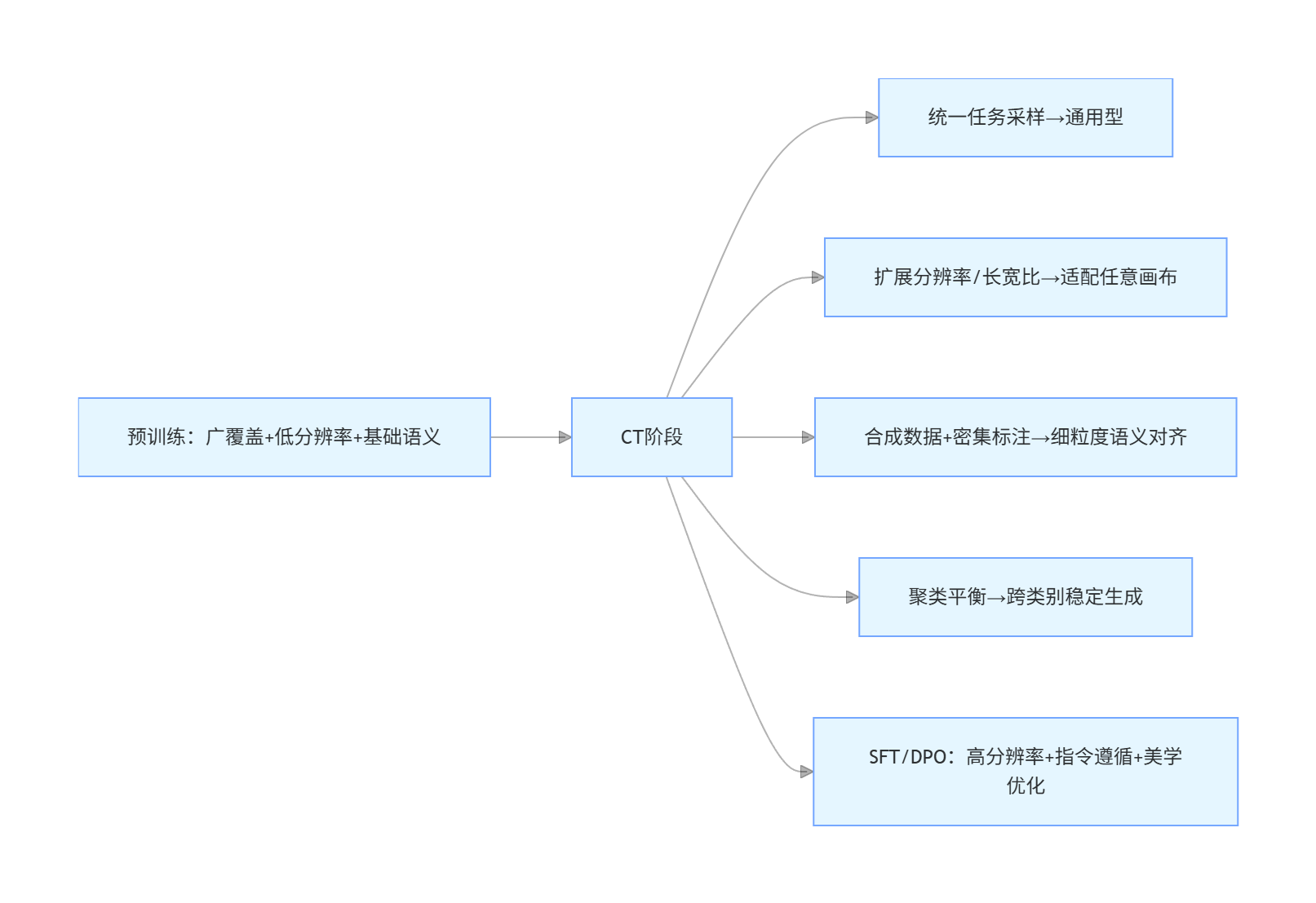
- 持续预训练阶段:做统一任务采样,扩展长宽比/分辨率适配,引入聚类均衡采样防模式坍缩。
- 监督训练阶段:强调高保真 1024 数据、强指令对齐与长尾重采样,配合低学习率和 EMA。
- 强化学习阶段:包含 DPO+PSR、Mix-Policy、Diffusion NFT、LA-OCR 奖励与半困难样本挖掘等策略。
4.3 关键训练 tricks(我重点记的)
- Multi-Condition Aware Bucket Sampler:按长宽比与分辨率分桶,减少 padding 浪费;
- Stochastic Instruction Alignment:参考图 dropout、指令扰动,提升泛化;
- 分布式分层时间步采样:降低扩散训练中的采样偏置;
- Logit-Normal 损失加权:聚焦中间关键时间步,抑制两端无效梯度;
- EMA 权重平均:提升收敛稳定性和分布外鲁棒性。
此外,原文还讨论了“一致性损失”相关问题,尤其是 identity drift:
- 仅靠像素损失无法保证高层身份语义;
- 低噪声阶段强加身份约束会伤害纹理;
- 多人场景需要主体级对齐而非单主体方案。
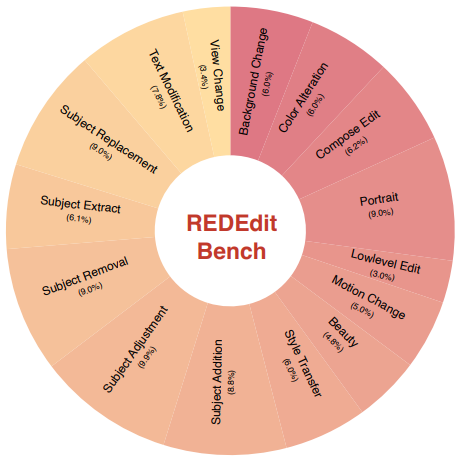
五、评测:REDEdit-Bench(为什么重要)
REDEdit-Bench 的定位是:尽量缩小“离线指标好看”与“真实体验好用”之间的差距。
- 1,673 对中英双语样本;
- 覆盖 15 类结构化编辑任务;
- 综合人工盲评与自动评测;
- 对文本编辑补充 OCR 与 VLM Judge。
评测流程我记下来的重点是:
- 三大维度综合评估:指令遵循、视觉自然、物理与细节一致性;
- 人工评测采用盲评与随机同屏,减少品牌/位置偏置;
- 文本编辑单独强化:OCR(编辑距离、完成率、字符准确率)+ VLM Judge(成功度、过度编辑、融合一致性)。
六、学习笔记与个人理解(阅读者)
这篇工作的价值,我认为不只在某个单点分数,而在于把“可工业化的图像编辑训练体系”搭得比较完整:数据治理、训练流程、评测体系三位一体。对于后来者,最可复用的是它的方法论框架。
如果后续继续跟踪这个方向,我会重点关注两点:
- REDEdit-Bench 与真实线上用户编辑分布的长期一致性;
- 在更小模型尺度下保留同等可控性与保真度的能力迁移。